

转载自知乎问题“目前比较好用的python开发工具是哪一个?”中旷野的回答。
大家好,我是旷野!
作为一名Python开发者,你是否经常被庞大的生态系统搞得头晕眼花?新工具层出不穷,老工具不断更新,到底哪些才是真正值得投入时间学习的必备库呢?
今天就为各位整理了2025年Python开发者必备的12大工具,这些工具正在重新定义Python开发的标准!无论你是刚入门的小白,还是经验丰富的老码农,这份工具清单都能让你的开发效率翻倍!
1. Python 3.11 - 更智能的Python
为什么要选择Python 3.11?
Python 3.11和3.12都带来了显著的性能提升,但3.11在稳定性和数据科学库兼容性方面表现更好,所以这个是我的首要推荐。
核心功能:精准定位错误位置
想象一下,以前遇到这种错误:
data =[1,4,8]
# 手误写成了datas
datas[0]=2 Python 3.9只会模糊地告诉你:
Traceback(most recent call last):
File"mistake.py", line 3,in<module>
datas[0]=2
NameError: name 'datas'isnotdefined 而Python 3.11就不一样了,能给你精确指出错误位置,妈妈再也不用担心我debug了:
Traceback(most recent call last):
File"mistake.py", line 3,in<module>
datas[0]=2
^^^^^
NameError: name 'datas'isnotdefined.Did you mean:'data'?调试过各种奇奇怪怪bug的都知道这一步定位有多么重要!都是血与泪啊。
⚡ 2. uv - Python管理的最佳方案
Python版本管理一直是个大问题,各种版本在电脑里乱放,越到后期越头疼,而这个uv就是一个能够替代pyenv + venv + pip的工具!

uv最强大的地方在于能够自动下载Python版本。没装Python 3.11?没关系:
# uv会自动下载Python 3.12并运行
uv run --python 3.12--no-project hello.py
# 第一次会显示:Using CPython 3.12.x (downloading...)
# 创建项目并锁定依赖
uv init my-project --python 3.11
cd my-project
uv add pandas requests # 自动生成uv.lock文件
# 全局安装工具
uv tool install pytest # 类似pipx但更快与Poetry对比:
- 速度: 比Poetry快10-100倍
- 兼容性: 支持现有的pyproject.toml
- 功能: Python管理 + 依赖管理 + 工具管理 全部搞定。
直接告别Python环境地狱,一条命令从零到运行!
3. Ruff - 代码美化大师
这个又是一个能抵千军万马的工具: Ruff = Black + Flake8 + isort + pyupgrade! 没错,四合一,非常高效好用。

Ruff用Rust编写,速度是传统工具的10-100倍,关键是功能全面:
# 问题代码示例
data = datas[0] # 未定义变量
import collections, os # 未使用导入 + 导入格式问题
def bad_function( x,y ):# 格式问题
return x+y 运行ruff check.--fix一键修复:
demo.py:1:8: F821 Undefined name `datas`
demo.py:2:8: F401 [*]`collections` imported but unused
demo.py:2:20: F401 [*]`os` imported but unused
demo.py:3:1: E302 [*]Expected2 blank lines, found 1
Found4 errors (3 fixable with the --fix option)Ruff的功能点:
- ✅ 代码格式化(替代Black)
- ✅ 导入排序(替代isort)
- ✅ 语法检查(替代Flake8)
- ✅ 代码升级(替代pyupgrade)
一行配置,直接告别工具链复杂度!
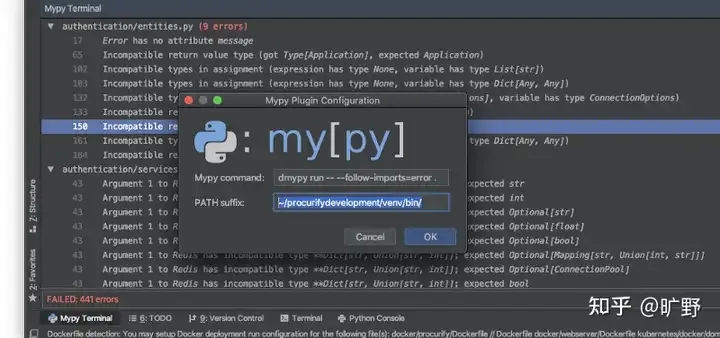
4. mypy - 古希腊掌管类型安全的神
静态分析发现bug,比单元测试覆盖更全面!
# mypy_example.py
def process(user: dict[str, str])->None:
# 这行代码有问题:字符串不能除以数字
result = user['name']/10
print(result)
user ={'name':'Alice','age':'25'}
process(user)运行mypy--strict mypy_example.py立即发现问题:
mypy_example.py:3: error:Unsupported operand types for/("str" and "int")
Found1 error in1 file (checked 1 source file) - 边界检查: 验证所有可能的代码路径,不只是测试覆盖的路径
- ⚡ 快速反馈: 无需运行代码就能发现类型错误
- 文档化: 类型注解即文档,提升代码可读性
- 重构安全: 大型项目重构时的安全网
静态类型检查是现代Python的标配,单元测试?往后稍一稍吧!
5. Pydantic - 让数据验证不再麻烦
Pydantic能让你告别字典,拥抱类型安全的数据模型!

from pydantic importBaseModel,ValidationError
import uuid
classUser(BaseModel):
id: uuid.UUID
name: str
# Pydantic V2 自动处理类型转换和验证
try:
# 有效的 UUID 字符串会被自动转换
user =User(id='123e4567-e89b-12d3-a456-426614174000', name='张三')
print(f"✅ 验证成功: {user}")
# 无效的 UUID 会触发清晰的错误
User(id='invalid-uuid', name='李四')
exceptValidationErroras e:
print(f"❌ 验证失败:\n{e}")Pydantic能够帮助你构建健壮API和数据处理流程,数据验证、类型安全、自动转换,全部搞定,还不快快学起来
️6. Typer - CLI开发神器
这是一个能够3行代码搞定命令行工具

import typer
app = typer.Typer()
@app.command()
def hello(name: str, age: int =20)->None:
"""
一个简单的CLI,会向你问好。
"""
print(f"你好 {name}!你今年 {age} 岁。")
# 将代码保存为 cli.py
# 运行 python cli.py --help 查看自动生成的帮助
# 运行 python cli.py "旷野" --age 23类型提示 + 自动补全 + 美观界面,CLI开发从未如此简单!
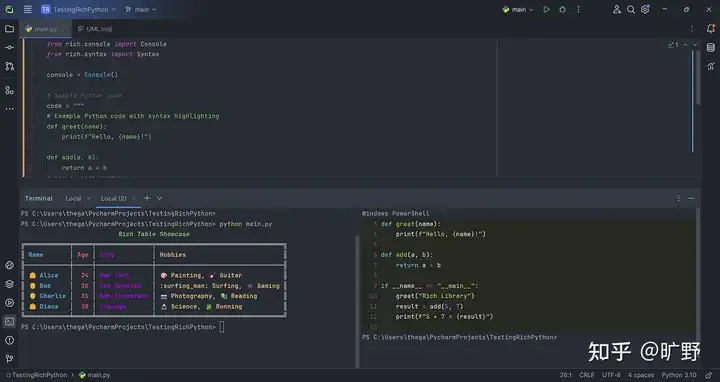
7. Rich - 终端美化
让你的终端输出美如画,当然要为了好看来学Rich啦!
from rich importprint
# 普通输出
print("普通的文本")
# Rich输出
print("[bold red]错误信息[/bold red] :warning:")
print("用户信息:",{'name':'张三','age':25})彩色输出、表格、进度条、语法高亮,让调试过程不再冰冷,给自己创造一点小情趣!
8. Polars - 数据处理的新星,放下手里的pandas吧
查询优化 + 并行处理 + 超内存数据集处理

Polars的核心优势不只是速度,更是智能查询优化:
import polars as pl
# 创建示例数据
df = pl.DataFrame({
'date':['2025-01-01','2025-01-02','2025-01-03'],
'sales':[1000,1200,950],
'region':['North','South','North']
})
# 懒加载 + 查询优化
query =(
df.lazy()# 开始懒加载,只构建查询计划
.with_columns([
pl.col("date").str.strptime(pl.Date).alias("date"),
pl.col("sales").cum_sum().alias("cumulative_sales"),
])
.group_by("region")
.agg([
pl.col("sales").mean().alias("avg_sales"),
pl.col("sales").count().alias("n_days"),
])
)
# 查看优化后的执行计划
print(query.explain())
# Polars会自动优化操作顺序,减少内存使用
result = query.collect()# 执行优化后的查询Polars vs Pandas:
- 性能: 多核并行,大文件处理快10-100倍
- 智能: 自动查询优化,像数据库一样思考
- 内存: 流式处理,支持大于内存的数据集
- 兼容: df.to_pandas()无缝转换
✅ 9. Pandera - 数据质量检查
帮你做一步数据验证,防患于未然

import pandera as pa
schema =DataFrameSchema({
"销售额":Column(int, checks=[
Check.greater_than(0),
Check.less_than(1000000)
]),
"地区":Column(str, checks=[
Check.isin(["北京","上海","深圳"])
])
})
# 自动验证数据质量
validated_df = schema(df)10. DuckDB - 一个分析型数据库
直接查询文件,无需加载到内存

DuckDB是专为分析工作负载设计的数据库,主要特点就是零拷贝文件查询:
作者:旷野
链接:https://www.zhihu.com/question/317758961/answer/1923959912158963183
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
import duckdb
import polars as pl
# 先创建测试数据
sales_data = pl.DataFrame({
"date":["2025-01-01","2025-01-02","2025-01-03"],
"product_id":[1,2,1],
"amount":[100,150,200],
})
sales_data.write_csv("sales.csv")
products_data = pl.DataFrame({
"product_id":[1,2],
"name":["Widget","Gadget"],
"category":["A","B"]
})
products_data.write_parquet("products.parquet")
# 直接查询多种文件格式,无需加载
con = duckdb.connect()
result = con.execute("""
WITH daily_sales AS (
SELECT
date,
product_id,
SUM(amount) as daily_total
FROM 'sales.csv'
GROUP BY date, product_id
)
SELECT
s.date,
p.name as product_name,
p.category,
s.daily_total
FROM daily_sales s
JOIN 'products.parquet' p ON s.product_id = p.product_id
ORDER BY s.date, p.name
""").df()DuckDB vs 传统数据库:
- 性能: 列式存储,分析查询比SQLite快100倍
- 内存友好: 流式处理,直接查询GB级文件
- 格式支持: CSV、Parquet、JSON一网打尽
- 单文件: 像SQLite一样,一个文件搞定数据库
11. Loguru - 日志记录专家
比标准库更简单、但是更好用的日志工具

from loguru import logger
# 一行代码搞定日志配置,自动轮转
logger.add("app.log", rotation="10 MB")
logger.info("程序启动,开始处理任务...")
try:
1/0
exceptZeroDivisionError:
# 自动捕获异常并记录详细堆栈
logger.exception("计算时发生错误")彩色输出、自动轮转、结构化日志,让调试过程清晰可见!
12. Marimo - 下一代Jupyter
**它解决了Jupyter的三大痛点:执行顺序、Git冲突、状态混乱!**想必各位或多或少也有遇到过这三个情况。

Marimo最大的改进就是响应式执行和纯Python存储:
import marimo
__generated_with ="0.10.12"
app = marimo.App(width="medium")
@app.cell
def _():
import pandas as pd
import plotly.express as px
# 数据自动同步,无需手动重新执行
data = pd.read_csv("sales.csv")
return data, pd, px
@app.cell
def _(data, px):
# 当data变化时,图表会自动更新
fig = px.bar(data, x="region", y="sales")
return fig,
if __name__ =="__main__":
app.run()Marimo vs Jupyter:
- 响应式: 变量更新时,依赖的单元格自动重新执行
- Git友好: 存储为纯Python文件,diff清晰可读
- ️状态安全: 消除隐藏状态,不再有”重启内核”的烦恼
彻底告别”这个单元格为什么不工作”的困扰
一个大总结:2025年Python工具箱清单(建议收藏以备不时之需)
| 工具 | 用途 | 核心优势 |
|---|---|---|
| Python 3.11 | 运行环境 | 智能错误提示、性能提升 |
| uv | 环境管理 | 一体化Python管理方案 |
| Ruff | 代码格式化 | 极速Rust引擎 |
| mypy | 类型检查 | 静态分析,提前发现bug |
| Pydantic | 数据验证 | 类型安全的数据模型 |
| Typer | CLI开发 | 类型驱动的命令行工具 |
| Rich | 终端美化 | 让输出更美观 |
| Polars | 数据处理 | 比Pandas更快的数据框 |
| Pandera | 数据验证 | 数据质量保证 |
| DuckDB | 数据查询 | 嵌入式分析数据库 |
| Loguru | 日志记录 | 简单强大的日志工具 |
| Marimo | 笔记本 | 响应式编程环境 |
旷野的一些组合建议
入门开发套装
- Python 3.11 + uv + Ruff + Rich
- 现代化基础环境 + 美观输出,建立良好开发习惯,调试过程不再枯燥
企业应用开发套装
- 基础套装 + mypy + Pydantic + Loguru
- 类型安全 + 数据验证 + 完善日志,帮助构建可维护的代码库
数据科学,机器学习套装
- 基础套装 + Polars + DuckDB + Pandera + Marimo
- 高性能数据处理 + 质量保证 + 更好的笔记本环境
如果此时间过长,文中的信息可能会失去时效性,甚至不再准确。